


Generación de números aleatorios
Marcos García González (h[e]rtz)
Date: Verano 2004
Documento facilitado por la realización de la asignatura Métodos informáticos de la física de segundo curso en la universidad autónoma de Barcelona en el transcurso del año 2003-2004.
1 Números uniformemente distribuidos
Un problema básico que nos encontramos habitualmente es el de obtener secuencias de números uniformemente distribuidos en un intervalo ![]() .
.
La diferentes posibilidades para resolver dicho problema son:
i) Buscar en tablas de números aleatorios publicadas (libros, internet ...);
ii) Observar un proceso físico tal como la desintegración radiactiva, el ruido eléctrico ...;
iii) Los lenguajes de programación y las hojas electrónicas incluyen una función para generarlos
iv) Mediante algorismos de generación de números aleatorios
Las principales ventajas de los generadores de números aleatorios son:
- Rapidez
- Comodidad
- Reproducibilidad
- Portabilidad
Y la desventaja fundamental:
- Las secuencias obtenidas no son realmente aleatorias, ya que se obtienen con operaciones deterministas. Solo podemos obtener secuencias pseudo-aleatorias, que a su vez satisfacen algunos criterios de aleatoriedad adecuados.
Los números generados deben cumplir ciertas características para que sean válidos. Dichas características son:
1. Uniformemente distribuidos.
2. Estadísticamente independientes.
3. Su media debe ser estadísticamente igual a 1/2.
4. Su varianza debe ser estadísticamente igual a 1/12.
5. Su periodo o ciclo de vida debe ser largo.
6. Deben ser generados a través de un método rápido.
7. Generados a través de un método que no requiera mucha capacidad de almacenamiento de la computadora.
Normalmente se utilizan números enteros, ya que su aritmética es exacta y rápida. Se generan enteros ![]() entre 0
y
entre 0
y ![]() , y
, y
![]() da valores reales en el intervarlo
da valores reales en el intervarlo ![]() .
.
En general los algoritmos utilizan relaciones de recurrencia del tipo
en el caso de recurrencia simple, o bien
para el caso de una recurrencia de orden
Se necesitará dar un valor inicial para comenzar el algoritmo (
1.1 Generadores de congruencia lineal (GCL)
Estos generadores son los más utilizados y los más conocidos. Se basan en la relación de recurrencia
donde
- Hay
- La secuencia es periodica: cuando vuelve a aparecer un número por segunda vez, la secuencia se vuelve a repetir. El periodo depende de los valores de
Recordemos que lo que nos interesa para trabajar con un buen generador de números aleatorios es que la distribución de los números obtenidos tiene que ser uniforme, no deben de haber correlaciones entre los terminos de la secuencia, el periodo debe ser lo más largo posible, y el algorismo debe ser de ejecución rápida.
1.1.1 Mejora de los generadores de congruencia lineal
Las limitaciones más importantes de los generadores son su periocidad (normalmente el periodo no suele ser más grande deSe parte de un generador que da enteros aleatorios entre 0 y
El elemento
1.2 Generadores de desplazamiento de bits
En estos generadores cada nuevo número entero aleatorio1.3 Generadores de Fibonacci
Las grandes ventajas de estos generadores es que son generadores muy rápidos que tienen un periodo muy largo. La fomentación teorica en la que se basan es diferente a la de los GCL. Los generadores de Fibonacci se basan en una recurrencia del tipo
donde
Otros tipos de generadores los podemos encontrar en:
- W.H. Press, S.A. Teukolski, W.T. Vetterling i B.P. Flannery, Numerical Recipes in C, Cambridge University Press.
-D.E. Knuth, The Art of computing programming, 2: Seminumerical Algorithms, Addison-Wesley.
Antes de aceptar un nuevo generador hace falta verificar que satisface una série de pruebas, lo que llamaremos pruebas de aleatoriedad.
1.4 Pruebas de aleatoriedad
Éstas consisten basicamente en realizar dos tipos de pruebas, empíricas y teoricas. Si los generadores superan estas pruebas, podremos asegurar que estamos ante un generador de números aleatorios bastante competente.Pruebas empíricas (sobre la muestra de la secuencia)
- Test de uniformidad: hace falta que los valores esten uniformemente distribuidos en
- Test serial: se generan parejas de valores
- Test de correlaciones: se determina la correlación entre números separados
Pruebas teoricas (sobre toda la secuencia): La sencillez de los generadores de congruencia lineal permiten demostrar propiedades importantes:
- Para determinar valores de
- Test espectral: si se forman vectores con
estos forman hiperplanos paralelos en el espacio k-dimensional. La separación
2 Distribuciones no uniformes
El problema a tratar será el de obtener una secuencia con densidad de probabilidad dadaPara resolver este problema utilizaremos el método del cambio de variable. Que concretamente consistirá en buscar una transformación
Si
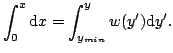
Si sabemos calcular la integral, obtenemos una relación del tipo
2.1 Ejemplos:
Distribución exponencial. Para obtener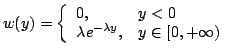 |
(1) |
entonces nos queda la ecuación
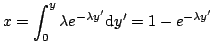
por lo tanto, el cambio adecuado será
Distribución normal. Para obtener
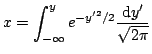
La integral no se puede resolver analíticamente, y menos aun invertir la relación para obtener
![$\displaystyle w(r,\theta) = p(x_1, x_2) \left\vert \frac{\partial (x_1,x_2)}{\p...
...rt = \frac{1}{2\pi} r e^{-r^2/2}, \ \ \theta \in [0,2\pi],\ \ r\in [0, +\infty)$](img61.png)
Por lo tanto,
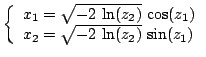 |
(2) |
Método de aceptación-rechazo: Es un método sencillo y general, aunque en ocasiones no muy eficiente.
Sea
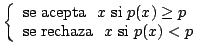 |
(3) |
De esta manera el valor